![[article invité] FME et la gestion de données SIG en biodiversité](https://naturagis.fr/wp-content/uploads/2020/02/illus_fme_ttt_data_biodiv.png)
Une étude cas : automatiser le traitement de données de biodiversité avec FME
Tout gestionnaire de données rêve d’automatiser ses traitements, parfois longs à paramétrer, souvent répétitifs… Et quoi de mieux qu’un bon vieux ETL pour manipuler de l’information géographique ? Mais qu’est-ce qu’un ETL… ? Cet article est là pour répondre à vos questions !
Dans cet article, c’est Loïc Guénin Randelli, expert FME freelance, qui nous fait l’honneur de nous présenter son outil de traitement de données de prédilection. Le tout richement illustré par un exemple d’application de traitement de données de biodiversité, directement issu de son expérience au sein de Sigogne, les Géo-services de la biodiversité en Bourgogne-Franche-Comté.
Cet article vous est proposé par :
Loïc Guénin Randelli, expert FME freelance
SITDI-France
Consulting, développements et formations FME
www.sitdi-france.fr
Mail : contact@sitdi-france.fr
Tél : 06.27.53.42.43
FME Kesako ?
FME : (Feature Manipulation Engine) est un outil graphique propriétaire créé par Safe Software (Canada). Ce dernier est classé dans la famille des ETL (Extract Transform Load). On dit de cet outil qu’il est le couteau Suisse du Géomaticien. Pour ma part, j’aime dire qu’un·e géomaticien·ne avec FME est un·e géomaticien·ne heureux-se !
- En Français ETL signifie : Extraire, Transformer, Charger
- Objectif : Être en mesure de pouvoir se connecter à de nombreux formats pour effectuer des traitements afin de corriger, modifier, enrichir des données pour ensuite charger en base ou créer des fichiers SIG ou non.
- FME a l’avantage d’être un ETL spatial ce qui lui permet de traiter des données géographiques. Il lit et écrit dans 400 formats environ.
- FME permet aussi d’améliorer l’interopérabilité entre les outils qui ne sont pas fait pour (à l’instar du SQL).

Formats
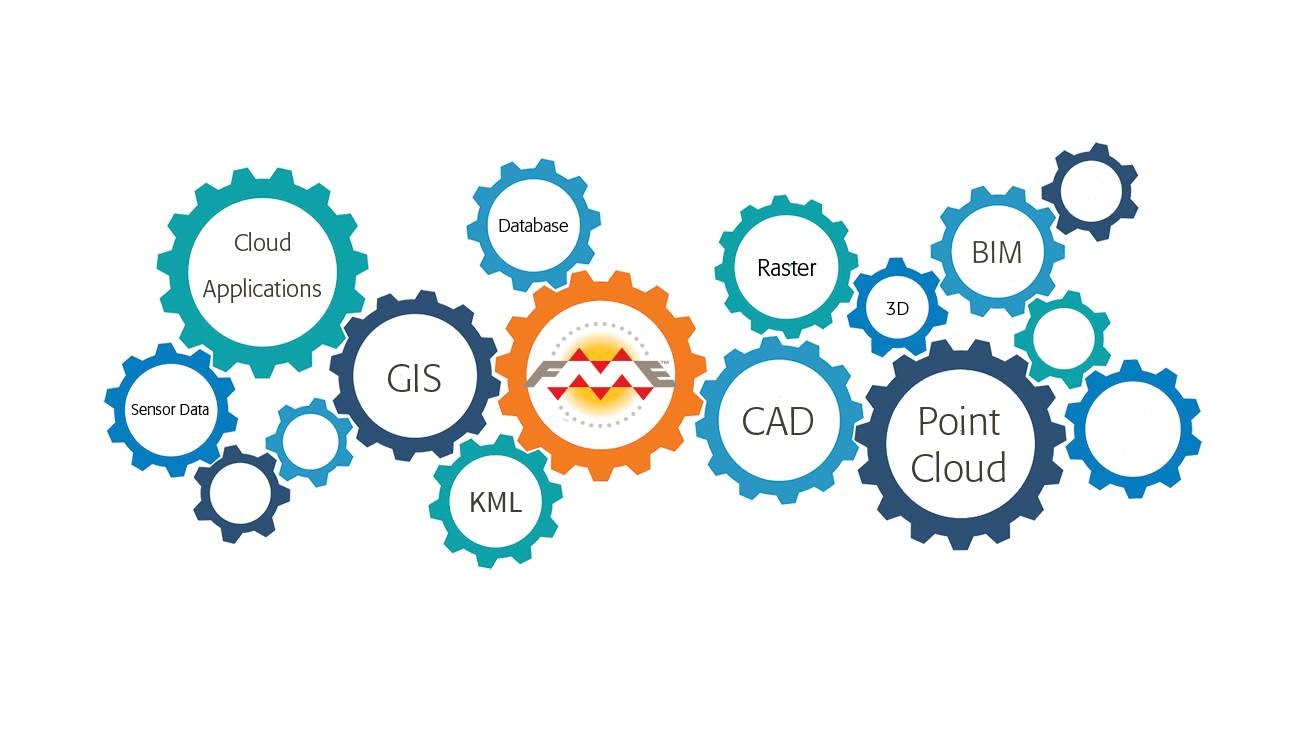
FME gère environ 400 formats :
- Raster (image)
- Vecteurs (Shape…)
- Services Web (WFS…)
- Bases de données spatiales ou non (PostgreSQL, Oracle…)
- Fichiers attributaires (Excel…)
Exemples de traitements possibles nativement avec FME :
- Transformations spatiales (découpage, fusion…)
- Traitements sur les attributs
- Jointures spatiales ou attributaires
- Traitements Raster
- Traitements 3D
- Vectorisation
- Corrections des géométries
- Transformation CAD vers SIG
- Statistiques (de bases ou via R)
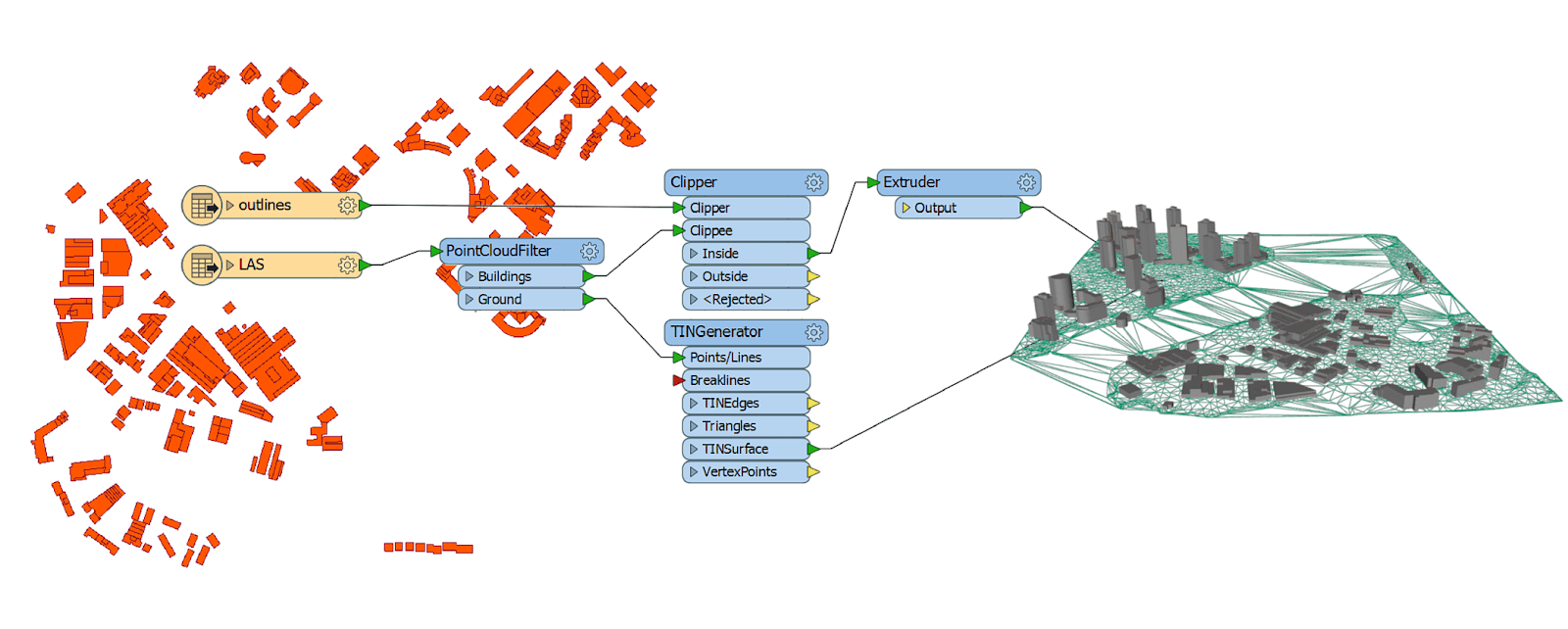
Exemple de traitements avec FME
FME Desktop : une suite logicielle
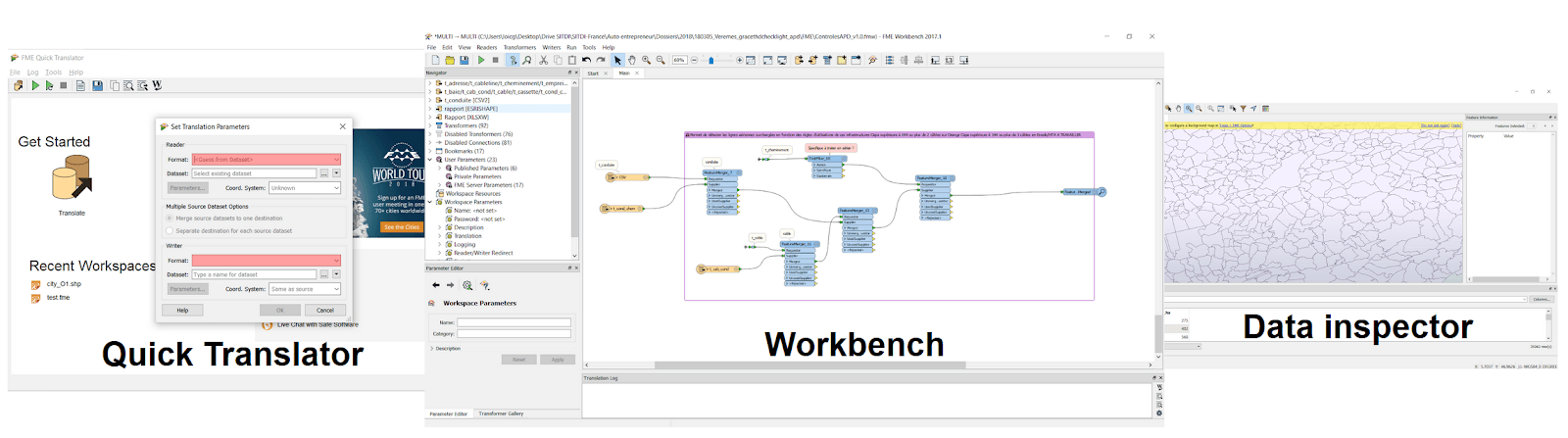
FME desktop propose plusieurs outils :
- Workbench : développement du script de manière graphique
- Data Inspector : Visualiser ses données vectorielles 2D, 3D, raster et attributaires
- Quick Translator : Transformations de formats rapide
FME : quel tarif ?
La version ESRI Edition permet d’écrire dans les Géodatabase et la Database Edition permet d’écrire dans Oracle spatial. Quant à la version Smallworld édition, cela permet de gérer les fichiers de cet outil.

FME Server
Notez que Safe software propose également un autre outil nommé FME Server. Cet outil ne permet pas de développer des scripts ETL mais permet de les proposer en tant que service sur Internet/Intranet. Des utilisateurs connectés peuvent alors profiter des scripts pour télécharger des données, convertir un format…enfin tout ce que sait faire FME et ce, sans posséder FME sur son poste.
FME server
Cas concret d’utilisation de FME en biodiversité
FME est capable de travailler avec tout type de données mais ici nous allons regarder un traitement dans le monde de la biodiversité.
Imaginons que nous récupérons des données d’observations de l’association LPO (Ligue de la Protection des Oiseaux). Ces données sont saisis majoritairement par des bénévoles via un site Internet et une application Android nommé NaturaList. Nous récupérons un fichier .CSV contenant les espèces observées, une localisation x/y au format GPS (WGS84) et un type de localisation (précis, lieu dit).
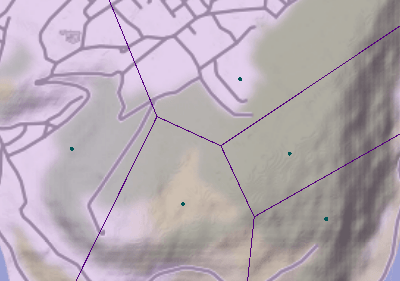
Lieu dit : spatialiser une zone inconnue
Ces données sont soit saisies à la localisation précise soit à un lieu dit. Les données précises seront exploitées comme un point. Un lieu dit est également représenté dans les données comme un point. Pour autant, un lieu dit est quelque chose de non délimité. C’est une zone assez flou au final qu’il est important de traiter au mieux pour que la représentation de l’information soit mieux répartie dans l’espace.
Lors de mon passage au sein de l’association Sigogne, nous avions utilisé une méthode appelée diagrammes de Voronoï pour représenter cet espace du lieu dit sur un polygone.
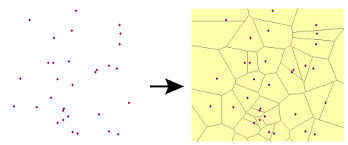
Exemple de création d’un diagramme de Voronoï
Sigogne
L’association Sigogne, a créé un outil web SIG en partenariat avec les associations naturalistes, la région Franche-Comté (et maintenant Bourgogne-Franche-Comté), l’Europe et la DREAL pour mettre à disposition aux aménageurs du territoire un outil gratuit permettant de créer des cartes et des synthèses de la connaissance à un instant T sur un morceau du territoire.
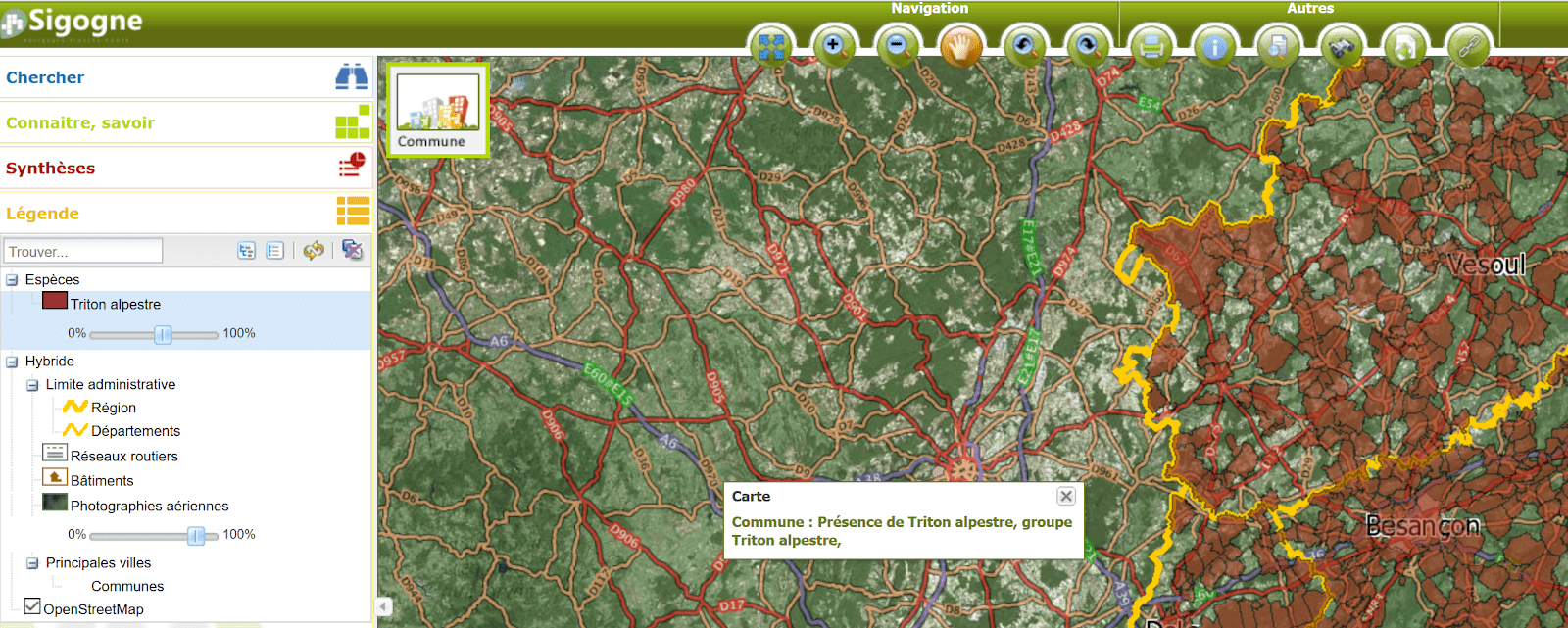
Géo-visualisateur de Sigogne
Dans le processus envisagé, nous devons créer le diagramme de Voronoï et appliquer le polygone à chaque observation lié au bon lieu dit. Cela génère une relation de type 1,n : 1 lieu dit est lié à n (plusieurs) observations. Pour stocker ce type d’information, une modélisation spécifique peut être menée. L’autre méthode consiste à multiplier le nombre d’objet par le nombre d’observations (moins efficace à priori et beaucoup plus consommateur de place en base de données).
Enfin, et pour finir le traitement, nous irons effectuer une jointure attributaire avec le référentiel TAXREF afin de récupérer les informations tels que nom commune, nom latin… Ce référentiel de référentiels est géré par le MNHN (Muséum National d’Histoire Naturel) via l’INPN (Inventaire National du Patrimoine Naturel).
Algorithmie
FME est un outil de scripting qui peut s’apparenter à bien des égards à un langage de développement. Le plus compliqué dans cet outil est de connaître le nom des fonctions qui sont appelées des Transformers, de les paramétrer et de les mettre dans le bon ordre.
Il est souvent très pertinent de réfléchir avec une logique d’algorithme qui permettra ensuite de définir les étapes logiques. Ensuite, les Transformers ayants des noms explicites, il est assez facile de s’y retrouver (un moteur de recherche Internet avec le mot FME aidera aussi).
Bien-sûr, comme tout outil, une formation reste incontournable pour démarrer dans de bonnes conditions et avec les bonnes pratiques.
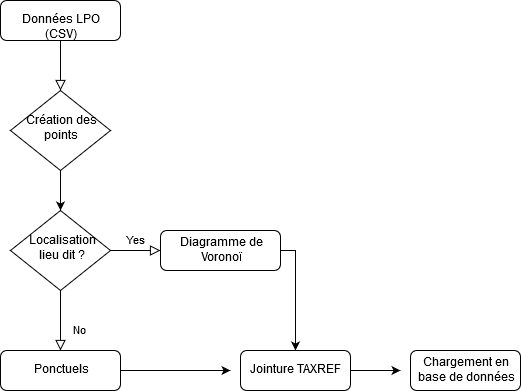
Schéma logique du script FME
Développement du script FME
Pour développer le script, nous partons des données sources appelées Reader dans FME. Il s’agit ici d’un fichier .CSV avec quelques attributs, un identifiant, un code TAXREF pour retrouver l’espèce, le type de localisation et les coordonnées de l’observation.
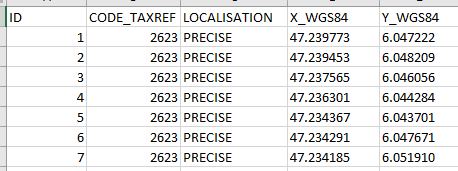
Données CSV
En faisant Ok, l’outil ajoute un Reader et liste les attributs trouvés. Nous sommes dans la lettre E de ETL (Extract). Bien évidemment FME peut avoir autant de Readers que voulu et dans tous les formats gérés par FME (400 pour rappel) !
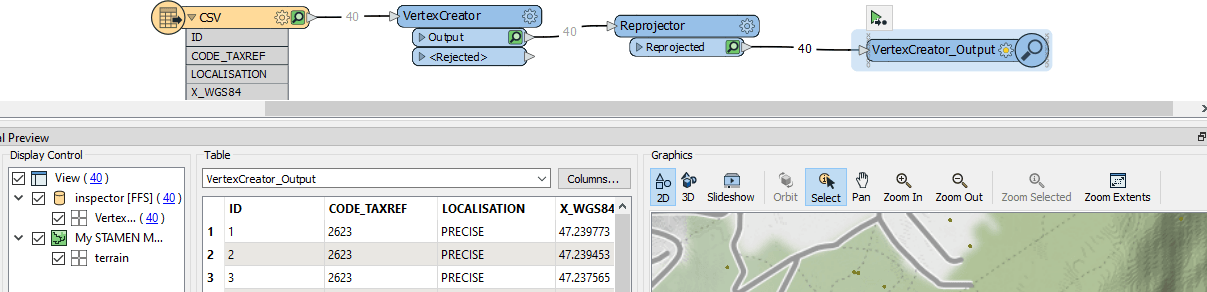
Suite à cela et suivant notre logique de traitement défini avant, nous allons créer un ponctuel à partir des coordonnées WGS84 disponibles dans le CSV. Pour ce faire, nous écrivons dans le centre de l’outil le nom du Transformer VerteXCreator.

Formez vous à FME
Data Inspector : l’outil de validation/débogage de votre script
Capture d’écran montrant le script FME et le résultat sur Data Inspector. On voit les points créés sur un fond de plan OpenStreetMap. Nos points sont bien projetés en Lambert93.
Il nous reste maintenant à discriminer le type de localisation pour créer ou non un diagramme de Voronoï sur ces points précis. Dans FME, le Transformer Tester, permet de trier les données via des conditions.
Ex : Si l’attribut ‘Localisation’ = ‘LIEU-DIT’ alors redirige les données vers le port Passed (condition vraie).

On remarque que mon Tester va répartir les données par rapport à mon test logique. A partir de là, je vais pouvoir faire un traitement différencié sur le port Passed et Failed.

Paramétrage du Tester
Script FME : ajout de VoronoiDiagrammer
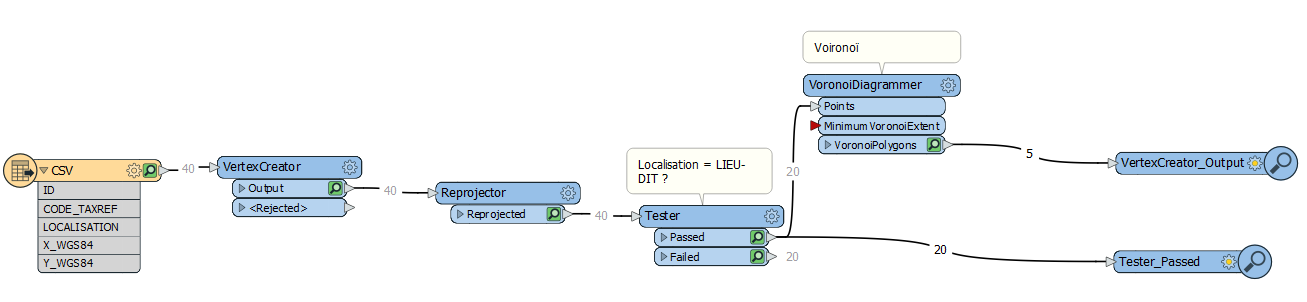
Il faut donc paramétrer VoronoiDiagrammer pour stocker la relation 1,n (plusieurs données par lieu dit). Ceci est géré par une liste dans FME (un tableau). C’est une notion un peu compliquée mais souvent indispensable dans ce cas.
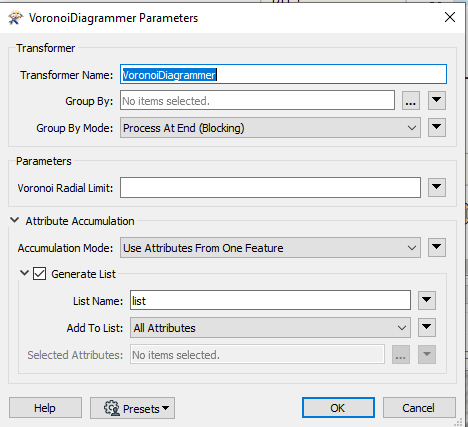
Visualisation de la méthode de stockage d’une liste sous FME : nom_liste{INDEX}ATTRIBUT > valeur
Attention, une liste commence toujours à l’index 0 !
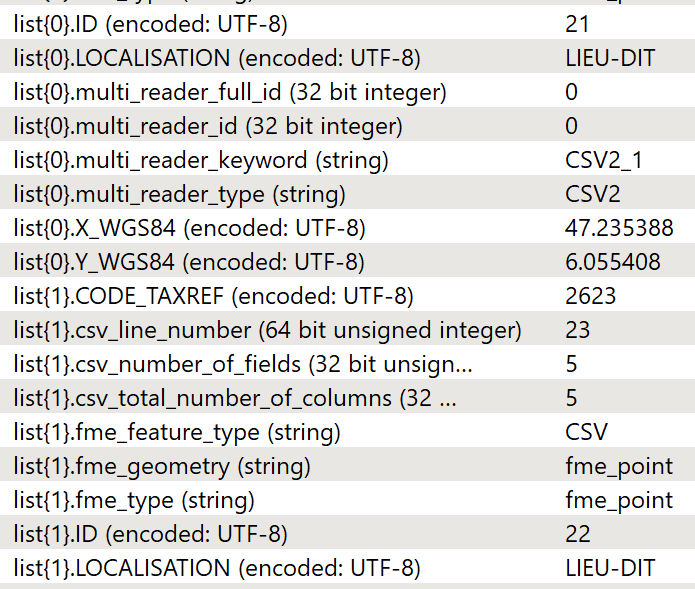
Jointure avec le référentiel Taxref
Dans notre processus, il nous reste encore une chose à faire : la jointure avec le référentiel TAXREF afin de récupérer les informations sur le nom de l’espèce, sa famille…
Dans FME, les Transformers FeatureMeger ou FeatureJoiner peuvent faire ce travail de jointure dite attributaire. La jointure permet de récupérer des informations sur un autre fichier via un attribut commun. Ici, notre attribut commun est le code TAXREF.
Pour effectuer la jointure, il faut au préalable ajouter un Reader du référentiel. C’est un fichier txt (vu comme un CSV dans FME) que l’on ajoute avec un glisser déposer. Une fois ajouté, il faut maintenant relier les données à notre FeatureMerger. Ce Transformer a deux ports d’entrée (Requestor et Supplier). Requestor est celui qui requête (nos données) et Supplier celui qui fournit (TAXREF). En effet, nous souhaitons injecter des informations dans nos données à partir d’une jointure sur le fichier TAXREF et non l’inverse.
Pour finir, il faut paramétrer FeatureMerger en expliquant à l’outil sur quel attribut la jointure doit être testée. Ici, il s’agit du côté Requestor de l’attribut CODE_TAXREF et côte Supplier de CD_NOM)

Paramétrage de la jointure
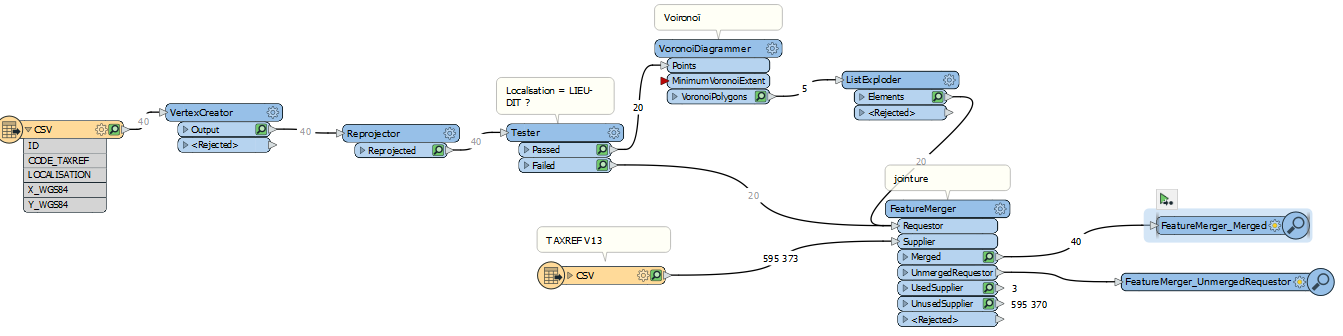
Nous retrouvons bien 40 données dans le port Merged ce qui nous permet de savoir que la jointure a fonctionné. Pour s’en persuader, nous pouvons regarder les données attributaires.

Nous y voyons maintenant le REGNE par exemple. Information que nous n’avions pas à l’origine. La jointure est fonctionnelle !
Édition du shapefile
Nous pouvons maintenant écrire un fichier Shapefile par exemple ou écrire dans une base de données comme PostgreSQL et son cartouche spatial PostGIS.
Pour ce faire, il faut ajouter un Writer du format désiré. FME est capable de créer la structure du fichier automatiquement. Bien-sûr, on pourra modifier cela en allant dans les paramètres du Writer.
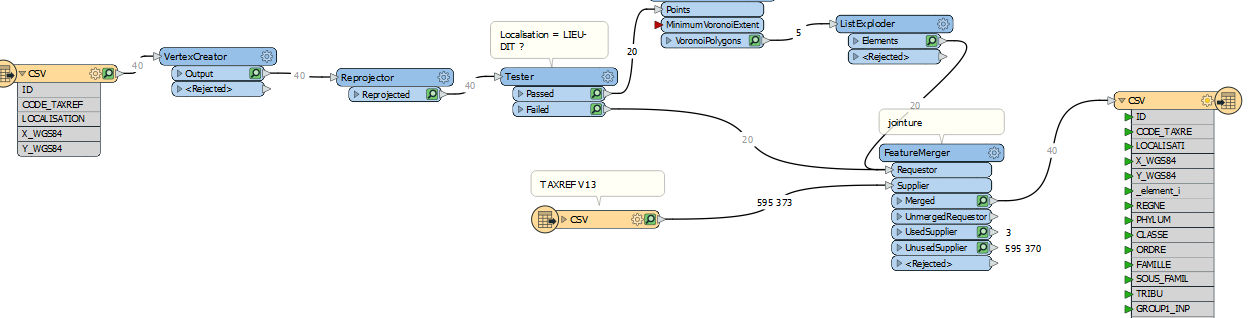
Projet terminé avec un Writer ShapeFile
Cet article se termine, j’espère vous avoir donné envie d’en savoir plus sur cet outil formidable qu’est FME. Je reste bien évidemment à votre disposition pour échanger sur cet outil, vous former et vous épauler pour des développements que ce soit dans le domaine de l’environnement ou non !
A bientôt, Loïc Guénin Randelli, expert ETL FME indépendant.
Auteur de l’article :
Loïc Guénin Randelli, expert FME freelance
SITDI-France
Consulting, développements et formations FME
www.sitdi-france.fr
Mail : contact@sitdi-france.fr
Tél : 06.27.53.42.43
Un petit coup de pouce ?
Cet article vous a plu et vous pensez qu’il pourrait être utile à quelqu’un d’autre ? Partagez le sur vos réseaux grâce aux boutons juste en dessous ! Merci !
![[Bases] Qu’est-ce que la géomatique ?](https://naturagis.fr/wp-content/uploads/2019/05/article_definition_geomatique-1-440x264.png)


{kind=link}